

Blog
3 kwi 2021, 20:03
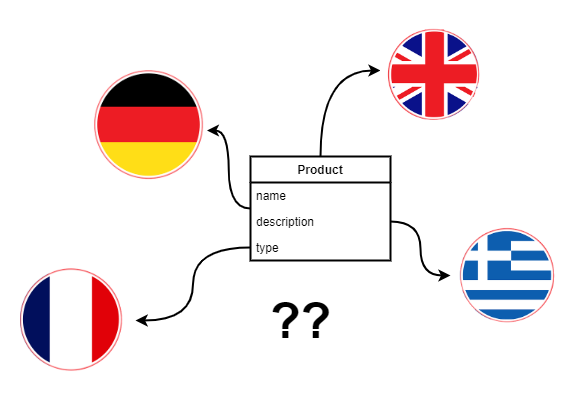
Kontynuując nasze rozważania jak optymalnie zaimplementować wyszukiwanie tekstowe na poziomie pojedynczych pól w systemie opiszemy koncepcję tabeli towarzyszącej z tłumaczeniami, którą będziemy tworzyć dla każdej klasy. Zastosujemy tutaj indeksy typu GIN / GiST opisane na początku niniejszej serii artykułów oraz spróbujemy zaimplementować opisywaną koncepcję w technologii Spring Data JPA, Hibernate oraz Postgres.
Śledź naszego bloga
![]()
![]()