

Blog
13 sie 2022, 22:17
Kontynuując nasze rozważania jak optymalnie zaimplementować wyszukiwanie tekstowe na poziomie pojedynczych pól w systemie wykorzystamy tym razem typ kolumny specyficzny dla Postgres - kolumnę HStore. Następnie założymy na niej indeksy typu GIN / GiST opisane na początku niniejszej serii artykułów oraz zintegrujemy HStore z Hibernate oraz Spring Data JPA.
3 kwi 2021, 20:03
Kontynuując nasze rozważania jak optymalnie zaimplementować wyszukiwanie tekstowe na poziomie pojedynczych pól w systemie opiszemy koncepcję tabeli towarzyszącej z tłumaczeniami, którą będziemy tworzyć dla każdej klasy. Zastosujemy tutaj indeksy typu GIN / GiST opisane na początku niniejszej serii artykułów oraz spróbujemy zaimplementować opisywaną koncepcję w technologii Spring Data JPA, Hibernate oraz Postgres.
27 wrz 2020, 13:00
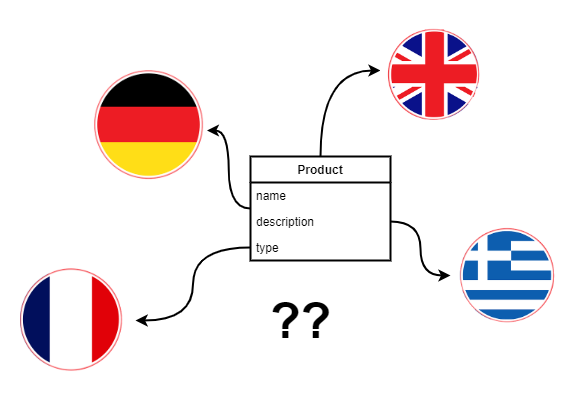
Systemy informatyczne, które operują w międzynarodowym środowisku, muszą często wspierać wielojęzyczne modele danych. Dla przykładu: użytkownicy systemu do zarządzania zakupami muszą mieć możliwość opisania pożądanych produktów w wielu językach ponieważ chcą otrzymać oferty od dostawców rezydujących w wielu państwach. Zaprojektowanie systemu, który będzie sobie dobrze radził z wyświetlaniem danych w języku danego użytkownika oraz także umożliwi mu wyszukiwane tekstowe jest nie lada wyzwaniem - wiele często stosowanych wzorców niesie za sobą dużo problemów wydajnościowych, które spowolnią cały system. W tym pierwszym z serii artykułów opiszemy jak Postgres ogólnie wspiera wyszukiwanie po tekście i zobaczymy jakie anty-wzorce pojawiają się najczęściej w wielojęzycznych modelach SQL.

21 paź 2019, 11:42
Dawno już minęły czasy gdy Java była zainstalowana na prawie każdym desktopie. Możemy jednak nadal dostarczać użytkownikom aplikacje napisane w Javie w przyjazny dla nich sposób. Od momentu wydania OpenJDK oraz OpenJFX 9 możemy wykorzystać modularyzację JVMa do łatwego zbudowania pliku wykonalnego z dołączonym do niego JVMem, który został skrojony do potrzeb naszej aplikacji. W tym artykule pokażemy jak sportowaliśmy naszą małą aplikacje desktopową PDF Decorator do OpenJDK 11 i wykorzystaliśmy takie narzędzia jak jlink i jpackage aby zacząć dostarczać naszą aplikacje bez wymagania oprogramowania firm trzecich na maszynach naszych użytkowników.

22 cze 2019, 10:13
Problem: chcemy aby zapytania do naszych encji ściągały tylko te pola, które są nam potrzebne w danej sytuacji (np. do pokazania w specyficznej tabeli w UI).
Wymaganie: nasze rozwiązanie musi mieć możliwość przyjęcia dowolnej kompozycji filtrów.
Możliwe rozwiązania: Named Entity Graph ze standardu JPA lub Projections - mechanizm z Spring Data.
Zbadajmy je!
Śledź naszego bloga
![]()
![]()