

Kontynuując nasze rozważania, jak optymalnie zaimplementować wyszukiwanie tekstowe na poziomie pojedynczych pól w systemie, wykorzystamy tym razem typ kolumny specyficzny dla Postgres - kolumnę HStore. Następnie założymy na niej indeksy typu GIN / GiST opisane na początku niniejszej serii artykułów oraz zintegrujemy HStore z Hibernate oraz Spring Data JPA.
Spis treści
Ten wpis jest częścią serii artykułów o internacjonalizacji danych ze wsparciem dla wyszukiwania tekstowego:
- Indeksy dostepne w Postgres oraz antywzorce
- Wydajna internacjonalizacja w PostgreSQL + Hibernate / JPA:
- Tabela towarzysząca z tłumaczeniami
- Kolumna HStore z tłumaczeniami - obecnie czytasz
Klucze językowe w HStore
HStore to specjalny typ danych w Postgres, który umożliwia nam w każdym wierszu przechować mapę klucz ‑ wartość. Dzięki temu dla każdego pola (jak np. nazwa produktu) możemy dodać towarzyszącą kolumnę z mapą: kod języka - tekst w danym języku. Przykład tabeli wykorzystującej ten koncept:

W powyższym przykładzie zakładamy że w kolumnie Name przechowuję nazwę w domyślnym języku organizacji, a w NameTranslations mamy tłumaczenia dla wszelkich innych języków.
Żeby móc korzystać z HStore w danej bazie Postgres trzeba uprzednio włączyć odpowiednie rozszerzenie:
CREATE EXTENSION hstore;
Integracja HStore z JPA / Hibernate
Java Persistence API zgodnie ze swoją zasadą neutralności nie wspiera HStore, który jest typem specyficznym dla bazy danych Postgres. Można jednak bardzo łatwo rozszerzyć funkcjonalność Hibernate aby móc pracować z tym typem zarówno na poziomie JPQL, Criteria API, a nawet generacji DDL. Pierwsze co musimy zrobić do dodać nasz UserType dla HStore.
HStoreType.java
/**
* Custom Hibernate {@link UserType} used to convert between a {@link Map}
* and PostgreSQL {@code hstore} data type.
*/
public class HStoreType implements UserType {
/**
* PostgreSQL {@code hstore} field separator token.
*/
private static final String HSTORE_SEPARATOR_TOKEN = "=>";
/**
* {@link Pattern} used to find and split {@code hstore} entries.
*/
private static final Pattern HSTORE_ENTRY_PATTERN = Pattern.compile(
String.format("\"(.*)\"%s\"(.*)\"", HSTORE_SEPARATOR_TOKEN)
);
public static final int SQL_TYPE = Types.OTHER;
@Override
public int[] sqlTypes() {
return new int[] { SQL_TYPE };
}
@SuppressWarnings("rawtypes")
@Override
public Class returnedClass() {
return Map.class;
}
@Override
public boolean equals(final Object x, final Object y) throws HibernateException {
return x.equals(y);
}
@Override
public int hashCode(final Object x) throws HibernateException {
return x.hashCode();
}
@Override
public Object nullSafeGet(final ResultSet rs, final String[] names,
final SharedSessionContractImplementor session, final Object owner)
throws HibernateException, SQLException {
return convertToEntityAttribute(rs.getString(names[0]));
}
@SuppressWarnings("unchecked")
@Override
public void nullSafeSet(final PreparedStatement st, final Object value, final int index,
final SharedSessionContractImplementor session) throws HibernateException, SQLException {
st.setObject(index, convertToDatabaseColumn((Map<String,Object>)value), SQL_TYPE);
}
@SuppressWarnings("unchecked")
@Override
public Object deepCopy(final Object value) throws HibernateException {
return new HashMap<String,Object>(((Map<String,Object>)value));
}
@Override
public boolean isMutable() {
return true;
}
@Override
public Serializable disassemble(final Object value) throws HibernateException {
return (Serializable) value;
}
@Override
public Object assemble(final Serializable cached, final Object owner)
throws HibernateException {
return cached;
}
@Override
public Object replace(final Object original, final Object target, final Object owner)
throws HibernateException {
return original;
}
private String convertToDatabaseColumn(final Map<String, Object> attribute) {
final StringBuilder builder = new StringBuilder();
for (final Map.Entry<String, Object> entry : attribute.entrySet()) {
if(builder.length() > 1) {
builder.append(", ");
}
builder.append("\"");
builder.append(entry.getKey());
builder.append("\"");
builder.append(HSTORE_SEPARATOR_TOKEN);
builder.append("\"");
builder.append(entry.getValue().toString());
builder.append("\"");
}
return builder.toString();
}
private Map<String, Object> convertToEntityAttribute(final String dbData) {
final Map<String, Object> data = new HashMap<String, Object>();
final StringTokenizer tokenizer = new StringTokenizer(dbData, ",");
while(tokenizer.hasMoreTokens()) {
final Matcher matcher = HSTORE_ENTRY_PATTERN.matcher(tokenizer.nextToken().trim());
if(matcher.find()) {
data.put(matcher.group(1), matcher.group(2));
}
}
return data;
}
}
Następnie musimy też dodać funkcje do zapytań w Hibernate, która umożliwi nam pobieranie wartości po kluczy z kolumny typu HStore. W tym celu dodajemy implementacje SQLFunction:
HStoreValueFunction.java
public class HStoreValueFunction implements SQLFunction {
@Override
public boolean hasArguments() {
return true;
}
@Override
public boolean hasParenthesesIfNoArguments() {
return false;
}
@Override
public Type getReturnType(Type type, Mapping mpng) throws QueryException {
return new StringType();
}
@Override
public String render(Type type, List args, SessionFactoryImplementor sfi) throws QueryException {
if (args.size() < 2) {
throw new IllegalArgumentException("2 arguments required");
}
String field = (String) args.get(0);
String key = (String) args.get(1);
return field + " -> " + key;
}
}
Spinamy wszystko z dialekt Postgresa:
ExpandedPostgresDialect.java
public class ExpandedPostgresDialect extends PostgreSQL95Dialect {
public ExpandedPostgresDialect() {
super();
registerFunction("hstoreValue", new HStoreValueFunction());
}
}
i ustawiamy nasz dialekt w konfiguracji Spring Boot:
spring.jpa.properties.hibernate.dialect=it.walczak.examples.in18jpa.ExpandedPostgresDialect
Model obiektowy w JPA
Po rozszerzeniu Hibernate o wsparcie dla HStore, możemy opracować model obiektowy, który będzie go wykorzystywał przy zapisie do bazy danych.
Product.java
@Entity
public class Product {
@Id
private UUID id = UUID.randomUUID();
@Embedded
private ProductDetails details;
public Product() { }
public Product(ProductDetails details) {
this.details = details;
}
public UUID getId() {
return id;
}
public void setId(UUID id) {
this.id = id;
}
public ProductDetails getDetails() {
return details;
}
public void setDetails(ProductDetails details) {
this.details = details;
}
}
ProductDetails.java
@Embeddable
public class ProductDetails {
private String code;
@Embedded
private TranslatableField name;
@Embedded
private TranslatableField description;
private BigDecimal price;
public String getCode() {
return code;
}
public void setCode(String code) {
this.code = code;
}
public TranslatableField getName() {
return name;
}
public void setName(TranslatableField name) {
this.name = name;
}
public TranslatableField getDescription() {
return description;
}
public void setDescription(TranslatableField description) {
this.description = description;
}
public BigDecimal getPrice() {
return price;
}
public void setPrice(BigDecimal price) {
this.price = price;
}
}
TranslatableField.java
@Embeddable
public class TranslatableField {
private String value;
@Type(type = "it.walczak.examples.in18jpa.concepts.b.hibernate.HStoreType")
@Column(columnDefinition = "hstore")
private Map<String, String> translationByLanguage = new HashMap<>();
public String getValue() {
return value;
}
public void setValue(String value) {
this.value = value;
}
public String getTranslation() {
String language = LocaleContextHolder.getLocale().getLanguage();
return getTranslationByLanguage().get(language);
}
public Map<String, String> getTranslationByLanguage() {
return translationByLanguage;
}
public void setTranslationByLanguage(Map<String, String> translationByLanguage) {
this.translationByLanguage = translationByLanguage;
}
}
Z racji że tworzymy dosyć generyczny embeddable, który będzie wykorzystany dla wielu pól w każdej encji, to warto ustawić w Spring Boot strategię nazewniczą kolumn bazy danych uwzględniające zagnieżdżenie obiektów.
spring:
jpa:
hibernate:
naming:
implicit-strategy: org.hibernate.boot.model.naming.ImplicitNamingStrategyComponentPathImpl
physical-strategy: org.hibernate.boot.model.naming.PhysicalNamingStrategyStandardImpl
Bez tego Hibernate w domyślnej konfiguracji próbowałby stworzyć wiele kolumn o nazwie "value" w jednej tabeli. Natomiast z powyższą konfiguracją będzie robił kolumny o nazwach:
details_name_value text; details_name_translation_by_language hstore; details_description_value text; details_description_translation_by_language hstore;
Usługa w Spring wyszukująca po tekście
Przetestujemy teraz wykorzystanie modelu w praktyce poprzez zaimplementowanie usługi Springowej umożliwiającej poprzez REST API:
- dodać oraz pobrać tłumaczenia danego produktu;
- wyszukać produkty po nazwie wg. danego języka.
Obsługę zapytań SQL, na której będzie bazować owa usługa, zaimplementujemy natomiast z pomocą Spring Data JPA.
ProductService.java
@RestController
@RequestMapping("products")
@Transactional
public class ProductService {
private final ProductRepostiory repostiory;
public ProductService(ProductRepostiory repostiory) {
this.repostiory = repostiory;
}
@PostMapping
public @ResponseBody Product add(@RequestBody ProductDetails details) {
return repostiory.save(new Product(details));
}
@PutMapping("{id}")
public @ResponseBody Product edit(
@PathVariable("id") UUID id, @RequestBody ProductDetails details
) {
Product product = repostiory.findById(id)
.orElseThrow(IdNotFoundException::new);
product.setDetails(details);
return repostiory.save(product);
}
@GetMapping("{id}")
public @ResponseBody Product get(@PathVariable("id") UUID id) {
return repostiory.findById(id)
.orElseThrow(IdNotFoundException::new);
}
@GetMapping
public @ResponseBody List<Product> find(
@RequestParam("name") String name
) {
return repostiory.findByNameLocalized(
name, LocaleContextHolder.getLocale().getLanguage(),
PageRequest.of(0, 100)
);
}
}
ProductRepostiory.java
public interface ProductRepostiory extends JpaRepository<Product, UUID> {
@Query(
value = "select p from Product p "
+ "where lower(p.details.name.value) like concat('%', lower(?1), '%') "
+ "or lower(hstoreValue(p.details.name.translationsByLanguage, ?2)) "
+ "like concat('%', lower(?1), '%')"
)
public List<Product> findByNameLocalized(String name, String language, Pageable pageable);
}
Indeksy w Postgres oraz testy wydajności
Biblioteka Hibernate na podstawie modelu z adnotacjami JPA wygeneruje nam tabele SQL, jednak nie zapewni optymalizacji. Samodzielnie musimy zadbać o dodanie do Postgres indeksów typu GIN, o których wspomnieliśmy w pierwszym artykule z serii.
CREATE EXTENSION IF NOT EXISTS pg_trgm; CREATE INDEX product_details_name_idx ON Product USING GIN (lower(details_name_value) gin_trgm_ops); CREATE INDEX product_translated_name_idx ON Product USING GIN (lower(details_name_translationbylanguage -> 'pl') gin_trgm_ops); -- indexes for other languages if needed ...
Jak widać po powyższym przykładzie trzeba tworzyć oddzielny indeks per język. Ma to swoje plusy i minusy. Z jednej strony musimy robić wiele indeksów z wycinkiem danych. Z drugiej natomiast mamy nad tym większą kontrolę i możemy robić indeksy tylko dla najpopularniejszych języków pośród naszych użytkowników. Ponadto, wyszukiwanie zawsze dzieje się w obrębie jednego języka, więc też jednego dobrze wyspecjalizowanego indeksu związanego z tym że językiem.
Analogicznie jak w poprzednie koncepcji zasilimy sobie bazę danych przy pomocy skryptu Gatlingowego.
class ConceptBPopulateSimulation extends In18jpaSimulation {
val scn = scenario("Concept B - Populate")
.repeat(100000)(
feed(createFeeder())
.exec(
http("add-product")
.post("/products")
.body(StringBody(
"""
| {
| "code": "${code}",
| "name": {
| "value" : "${name}",
| "translationByLanguage" : {
| "pl" : "${nameTranslation}"
| }
| },
| "description": {
| "value": "${description}",
| "translationByLanguage" : {
| "pl" : "${descriptionTranslation}"
| }
| },
| "price": ${price}
| }
""".stripMargin))
.check(status.is(200))
.check(jsonPath("$.id").saveAs("id"))
)
)
setUp(
scn.inject(
atOnceUsers(1)
)
.protocols(createHttpProtocol())
)
}
Upewnijmy się że nasze indeksy są wykorzystywane:
explain select
product0_.id as id1_0_,
product0_.details_code as details_2_0_,
product0_.details_description_translationByLanguage as details_3_0_,
product0_.details_description_value as details_4_0_,
product0_.details_name_translationByLanguage as details_5_0_,
product0_.details_name_value as details_6_0_,
product0_.details_price as details_7_0_
from Product product0_
where lower(product0_.details_name_value) like ('%'||lower('aaa')||'%')
or lower(product0_.details_name_translationByLanguage -> 'pl') like ('%'||lower('aaa')||'%')
zwraca nam
Bitmap Heap Scan on product product0_ (cost=175.84..5669.84 rows=15680 width=173)
Recheck Cond: ((lower((details_name_value)::text) ~~ '%aaa%'::text) OR (lower((details_name_translationbylanguage -> 'pl'::text)) ~~ '%aaa%'::text))
-> BitmapOr (cost=175.84..175.84 rows=16000 width=0)
-> Bitmap Index Scan on product_details_name_idx (cost=0.00..84.00 rows=8000 width=0)
Index Cond: (lower((details_name_value)::text) ~~ '%aaa%'::text)
-> Bitmap Index Scan on product_translated_name_idx (cost=0.00..84.00 rows=8000 width=0)
Index Cond: (lower((details_name_translationbylanguage -> 'pl'::text)) ~~ '%aaa%'::text)
Korzysta z indeksu zgodnie z założeniami. Wykonajmy teraz żądanie HTTP do naszego API.
Request
GET /products?name=abcd Accept: application/json Accept-Language: pl-PL
Response
HTTP/1.1 200
Content-Type: application/json
[
{
"id": "b38c0f99-705a-4f2f-bc99-3807a2d0ba9e",
"details": {
"code": "wsZ",
"name": {
"value": "mIc9MYht",
"translationByLanguage": {
"pl": "NaBCDaq"
},
"translation": "NaBCDaq"
},
"description": {
"value": "LGl0O0S7EuYF4yX1EArDvZQiH79X0j4nj4Y2aVFUlH8zlzg",
"translationByLanguage": {
"pl": "ptXKAbiuSzV1EzhdFxmltFq"
},
"translation": "ptXKAbiuSzV1EzhdFxmltFq"
},
"price": 0.95
}
},
{
"id": "5fbec3a2-f41b-466c-8bcc-c8f4991859d4",
"details": {
"code": "",
"name": {
"value": "pfr46Abcdxa7cs",
"translationByLanguage": {
"pl": "boFVzZF99yJSHVcufK7"
},
"translation": "boFVzZF99yJSHVcufK7"
},
"description": {
"value": "Sp1L0hy3EoBFmZtM",
"translationByLanguage": {
"pl": "A5CXGbMcpOsID1u7zjoDxP5RSuGpIN2GA"
},
"translation": "A5CXGbMcpOsID1u7zjoDxP5RSuGpIN2GA"
},
"price": 0.38
}
}
]
Czas wykonania od 5 do 30 ms, więc jesteśmy na dobrej drodze. Jeżeli usuniemy indeksy czas zwiększa się w okolice ~150 ms. Zróbmy zatem teraz pełen test wydajnościowy. W tym celu napiszemy dwa bardziej rozszerzone skrypty Gatlina:
- Just search - symulacja gdzie równolegle dzieją się tylko wyszukiwania
- Full simulation - symulacja gdzie równolegle dzieją się zarówno zapisy jak i wyszukiwania w proporcji 1:1
Just search
class ConceptBJustSearchSimulation extends In18jpaSimulation {
val scn = scenario("Concept B - just search simulation")
.repeat(100)(
feed(createFeeder())
.exec(
http("find-by-name-part")
.get("/products?name=${namePart}")
.check(status.is(200))
)
)
setUp(
scn.inject(
rampUsers(15) during (5 seconds)
)
.protocols(createHttpProtocol())
)
}
Full simulation
class ConceptBFullSimulation extends In18jpaSimulation {
val scn = scenario("Concept B - Full simulation")
.repeat(10)(
feed(createFeeder())
.exec(
http("add-product")
.post("/products")
.body(StringBody(
"""
| {
| "code": "${code}",
| "name": {
| "value" : "${name}"
| },
| "description": {
| "value": "${description}"
| },
| "price": ${price}
| }
""".stripMargin))
.check(status.is(200))
.check(jsonPath("$.id").saveAs("id"))
)
.exec(
http("add-translation")
.put("/products/${id}")
.body(StringBody(
"""
| {
| "code": "${code}",
| "name": {
| "value" : "${name}",
| "translationByLanguage" : {
| "pl" : "${nameTranslation}"
| }
| },
| "description": {
| "value": "${description}",
| "translationByLanguage" : {
| "pl" : "${descriptionTranslation}"
| }
| },
| "price": ${price}
| }
""".stripMargin))
)
.exec(
http("get-translated")
.get("/products/${id}")
.check(status.is(200))
)
.exec(
http("find-by-name-part")
.get("/products?name=${namePart}")
.check(status.is(200))
)
)
setUp(
scn.inject(
rampUsers(20) during (5 seconds)
)
.protocols(createHttpProtocol())
)
}
Skrypty te uruchomimy raz na bazie z indeksami i raz na bazie bez indeksów. Raz na bazie z 100'000 produktów, a raz z 500'000 produktów. Zestawienie czasów odpowiedzi zaprezentowane poniżej.
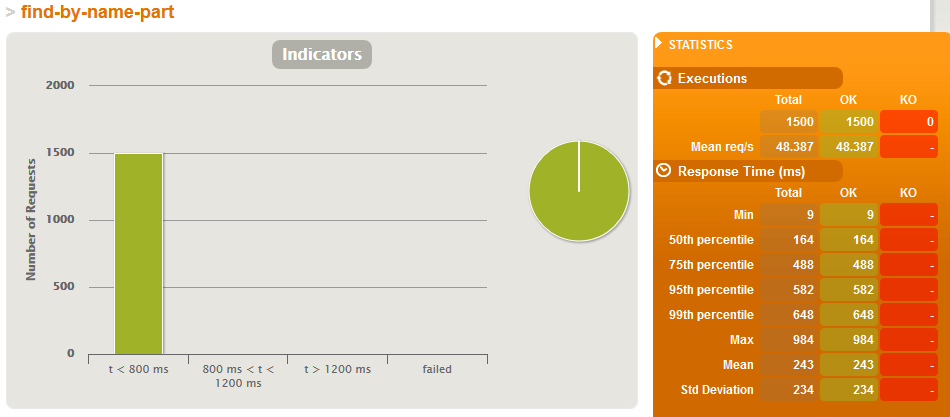
Wyniki dla 100'000 produktów
Just search simulation - BEZ indeksów
Just search simulation - Z indeksami
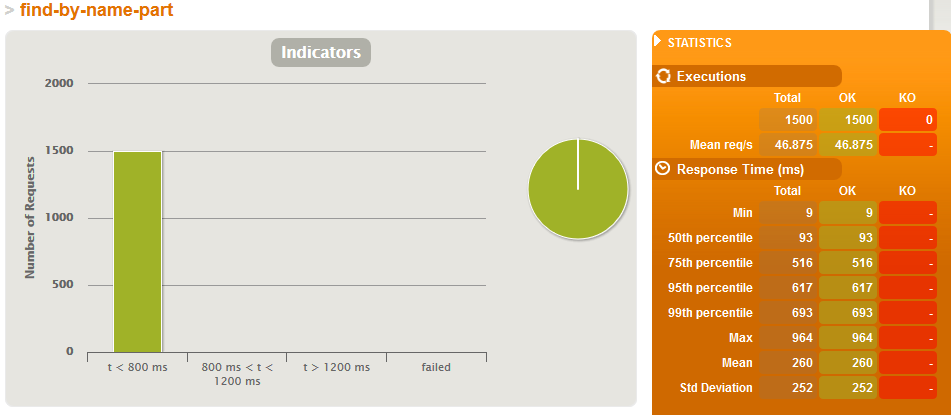
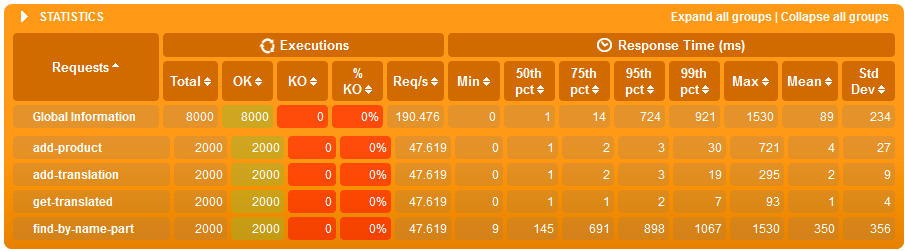
Wyniki dla 500'000 produktów
Just search simulation - BEZ indeksów
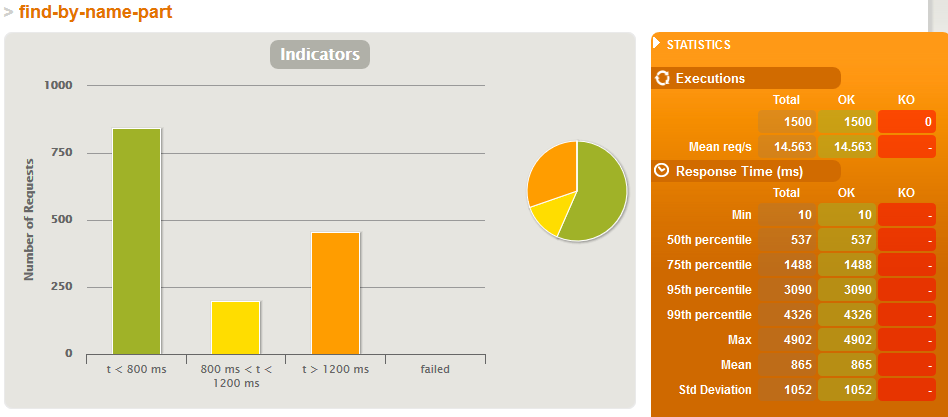
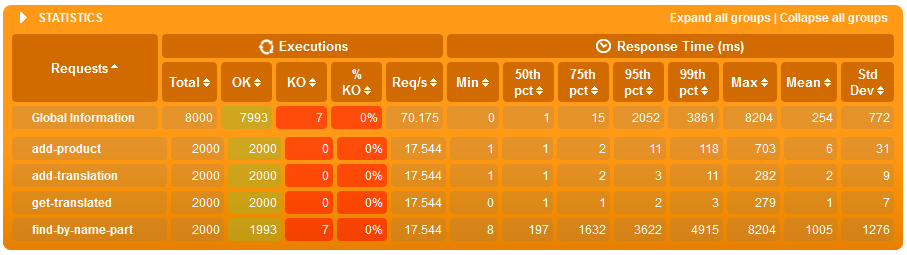
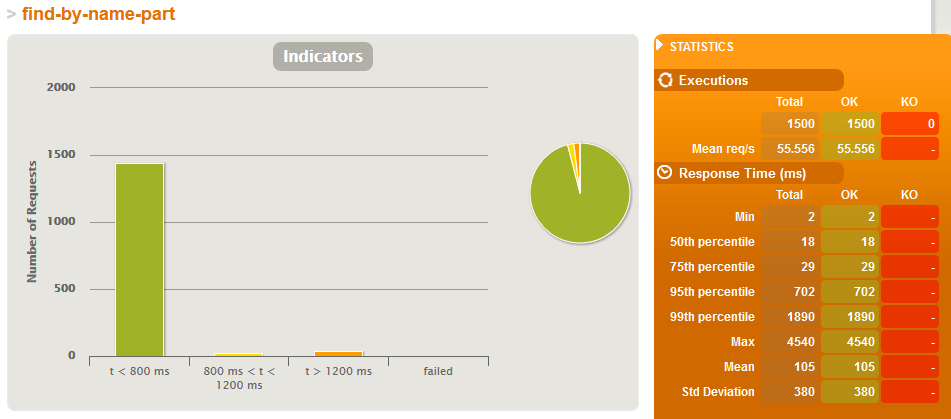
Just search simulation - Z indeksami
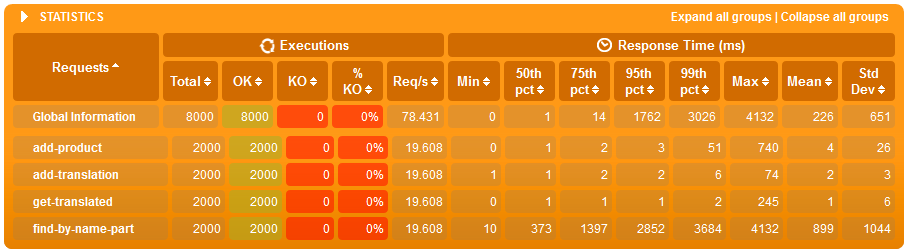
Wnioski
- koncepcja oparta na HStore okazała się o wiele łatwiejszą w integracji z JPA i Spring Data, aniżeli tabela towarzysząca z tłumaczeniami
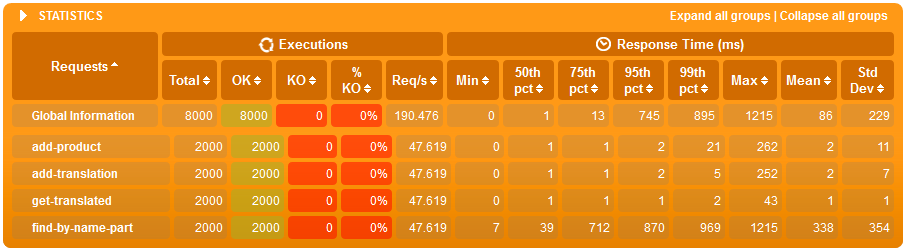
- przy tabelach z 100'000 wierszami indeksy mają marginalny wpływ na wydajność, zarówno wyszukiwania po tekście jaki i zapisów przy obciążonym systemie,
- różnice dopiero widać przy 500'000 wierszach gdzie:
- średni czas wyszukiwania po tekście w systemie obciążonym jedynie wyszukiwaniem jest 8x krótszy jeżeli są indeksy,
- w scenariuszu gdzie jest bardzo dużo zapisów (jeden zapis na wyszukiwanie), zarówno wyszukiwanie jak i zapis jest szybszy o 20% z indeksami - co ciekawe o ile zapis ma więcej roboty z indeksem to zaoszczędzony czas na wyszukiwaniu przełożył się tu na ostatecznie szybsze działanie usługi.
Kody źródłowe zastosowane w tym artykule można znaleźć na naszym repozytorium bitbucket.
Niniejszy artykuł kończy nasza serię. Jeżeli chciałbyś przeczytać naszą analizę od początku to przejdź do artykułu Internacjonalizacja danych z wyszukiwaniem tekstowym - indeksy w Postgres oraz antywzorce
Ten artykuł jest wynikiem naszej współpracy z Nextbuy - firmą dostarczającą w modelu SaaS platformę zakupową i przetargową, która łączy kupców i dostawców. Świadczymy dla nich usługi doradcze oraz wsparcie w pracach programistycznych. Jesteśmy wdzięczni, że zgodzili się upublicznić część dokumentów projektowo-rozwojowych powstałych, w wyniku tego. Możecie sprawdzić ich świetną platformę na www.nextbuy24.com
Śledź naszego bloga
![]()
![]()